

Dominik Vereno am Arbeitsplatz
As part of his bachelor’s project on test automation, Dominik Vereno worked on many millions of lines of code. The Salzburg University of Applied Sciences student, who started out at Porsche Informatik with a part-time position in customer support, has now made the transition to software developer. He explains what his bachelor’s project involved, and why IT sometimes feels like climbing a mountain …
How did you choose the topic for your internship, and why did you opt for specifically this project at Porsche Informatik?
I actually started working in th eCROSS 2 department after a period spent working in support through the study.work.support. program, so it seemed an obvious move to do my bachelor’s internship here too. The first part of the project was carried out in coordination with the head of department: we discussed various topics and issues, and I was very enthusiastic about the idea of optimising execution times for unit tests, as there are numerous measurable aspects involved in that. Unit tests are an important part of quality assurance. You can use time measurements and statistical evaluation of measured values to address the issue in the form of an academic study.
How much freedom were you given in terms of structuring your project?
The project itself took shape after we looked at various options. The starting point was a fairly general problem: not just solving a specific problem in a specific way, but finding my own way of solving the problem. The actual method of implementation was left entirely up to me.

Dominik Vereno and blogger Wolfgang Brandner.
What exactly was the problem, and what was your approach?
In concrete terms, the problem was that performing unit tests in CROSS 2 development was taking too long. For continuous integration, it’s important that the verification builds, which are performed when a change is checked in, run quickly, so that the developers receive rapid feedback. The original assumption was that the database connections which are built into the unit tests were causing significant lags. Eventually, I discovered that the set-up of those connections does make a minor difference, but isn’t the sole cause of the lags. A large part of the execution time is in fact overhead, and only a minor part of that is used to execute the test methods. So a simpler approach is to ensure the overhead comes up only once and not separately for all sub-systems.
What precisely are the benefits for us?
The benefits are that the developers now receive feedback quickly on whether everything is built correctly and whether unit tests break when a change is made. By dramatically reducing the unit test execution time, you can significantly speed up that feedback. That was just the first part of the bachelor’s project.
And the second part?
A solution to the problem was found fairly quickly, so it was decided that a further project should be added. Originally, the project was dubbed “social code analysis”. The idea here is that you take into account not just static metrics regarding the code, but also the change history. Basically, you’re looking at the complexity of the code – which code is complex, and which code has undergone frequent changes. The fact is: a code which undergoes frequent changes is more likely to contain an error than a code that has remained unchanged in the code base for ten years. Another issue is this: which of these complex classes, which themselves frequently undergo change, have poor test coverage? For which classes and code segments does one urgently need to improve test coverage? In which areas can one achieve the most benefits in terms of error detection? That’s actually what made my bachelor’s project unique and distinguished it from other works.
It sounds as though social code analysis has a human aspect to it?
That’s right. If you just look at the code, you can assess complexity, length and the degree of branching. But with social code analysis, you can assess how, how often and by how many different developers the code has been modified, and how those modifications interrelate chronologically. For example, if within a short space of time a developer works on two different classes which are not dependent on each other, you can spot connections which might perhaps be hard to see if you were just using static observation.
How does that differ from conventional automated test approaches?
Especially in a large-scale system, you can find out where improvements to test coverage are most urgently needed, i.e. which are the problem classes. The task is to prioritise them. I only found few academic articles dealing with change history and change frequency, so in that respect, social code analysis is new territory.
Did you get the impression Porsche Informatik still needs to make progress in that regard, or did you find yourself in a test landscape in which much of the ground has already been covered?
I assessed code at a meta-level and didn’t have to make my way through a jungle of automated tests. Naturally, it’s always possible to improve test coverage. But in a system that has grown over a period of 15 years and contains 12 million lines of code, it’s correspondingly difficult for the developers themselves to maintain an overview. Where should one start if one wants to improve test coverage? Quantifying the classes or class characteristics at a more objective level allows someone unfamiliar with the terrain to make an effective assessment.
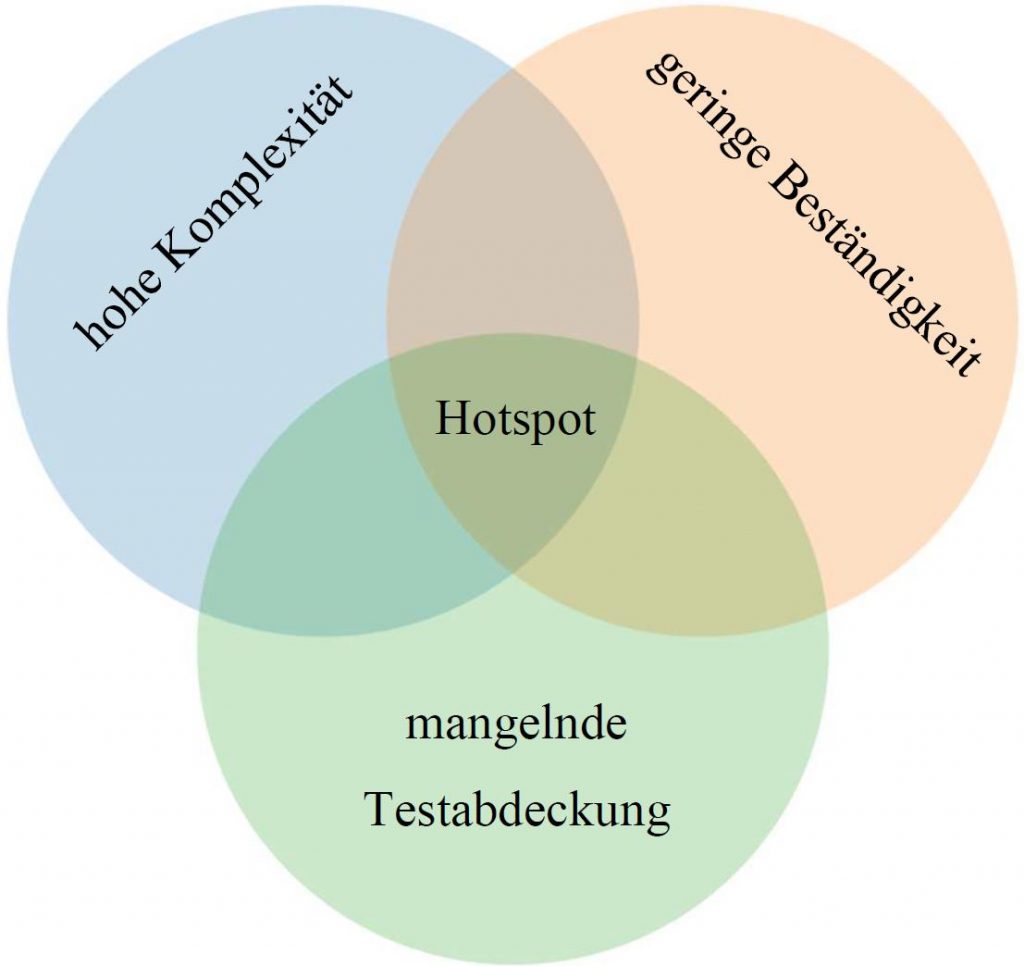
Code complexity, inconsistency and limited test coverage increase error probability.
Is this the first time you’ve worked on a live productive system?
I’m at the end of my bachelor degree now and naturally I have had some experience, but I’ve never worked on a large-scale productive system with such an extensive code base. I have used automated tests on my own projects and study projects, and before that I studied the field in detail as part of my own personal learning process.
In other words, your basic approach was academic, then you were confronted with a large-scale system with many millions of lines of code. How great a culture shock was that for you – the gulf between academic theory and a live productive system?
In an academic or theoretical context, obviously there’s a lot that is precisely that – theoretical. And the scale is different. On a big project at the University of Applied Sciences, you handle a lot yourself, and at the same time you’re also working collaboratively with colleagues. If you then arrive in a department where they’ve been working for many years on a particular system and which is therefore of a commensurate size, that’s something very different. You have to come to grips with the fact that you can actually only see and comprehend a tiny part of the huge software system. Well yes, that is a culture shock, especially if you have not worked before with a large-scale system that has grown over a period of time.
Did you find it hard adjusting to what you were confronted with? Like a mountain climber who has only climbed indoors and then finds himself on a real mountain …
I am not a climber, but I imagine the risk level on an indoor climbing wall must be very different from an actual mountain, and safety has to be taken all the more seriously. It’s certainly difficult to cope with initially. There are countless files where you can only see a tiny part, and then connections and function calls in entirely different classes and completely different sub-systems where you have no idea what the task is. What really helps is having a network of team colleagues who are willing to openly discuss issues and don’t mind if you pester them! Nonetheless, those types of questions have to be answered with tremendous patience and dedication.
Fellow climbers who can offer you safety gear …
Exactly, experienced climbers with safety lines, making sure you complete the climb yourself. Here at Porsche Informatik, everyone is very supportive.
Now that you have had your first official day of work following your internship, what is it like working on CROSS 2?
I possessed a good overview of framework components and the general structure already. What comes now are numerous aspects of day-to-day work processes, such as how activities are administered, code protection, testing and checking in. This is new ground for me and needs to be learned. During my internship, I worked very independently and had a lot of freedom, with many different potential avenues. I was free to make up my own mind. Now I’m part of a team where everybody has to play their part and adjust.
How about your own personal growth?
In my studies I intend to specialise in the fields of data science and robotics – I’m very interested in those areas.
Working and studying at the same time is a challenge, but clearly you are very practice-oriented.
What is great at Porsche Informatik is that I can gain a lot of valuable practical experience even while I’m still studying and starting out on my career. Once I have finished my studies, I’ll have not just an academic but also a professional background.
